
THE QUICK BRIEF
The Core Update:
NVIDIA published a production-ready framework for training specialized CLI agents using Reinforcement Learning with Verifiable Rewards (RLVR) and synthetic data generation eliminating the need for months of real-world usage collection.
Key Technical Specs:
- Base Model: Nemotron-Nano-9B-V2 (9 billion parameters)
- Training Efficiency: GRPO reduces VRAM usage by 80% vs traditional PPO
- Hardware Requirement: Single A100 GPU (80GB)
- Training Time: Hours instead of months for domain-specific CLI tools
- Reward Mechanism: Deterministic, code-based verification (binary ±1 rewards)
The Bottom Line:
This matters for DevOps teams and ML engineers building internal AI tooling. The framework enables rapid deployment of safe, domain-specific agents without waiting for organic data accumulation or accepting command-injection risks.
Why Traditional AI Agent Training Fails for Specialized CLI Tools
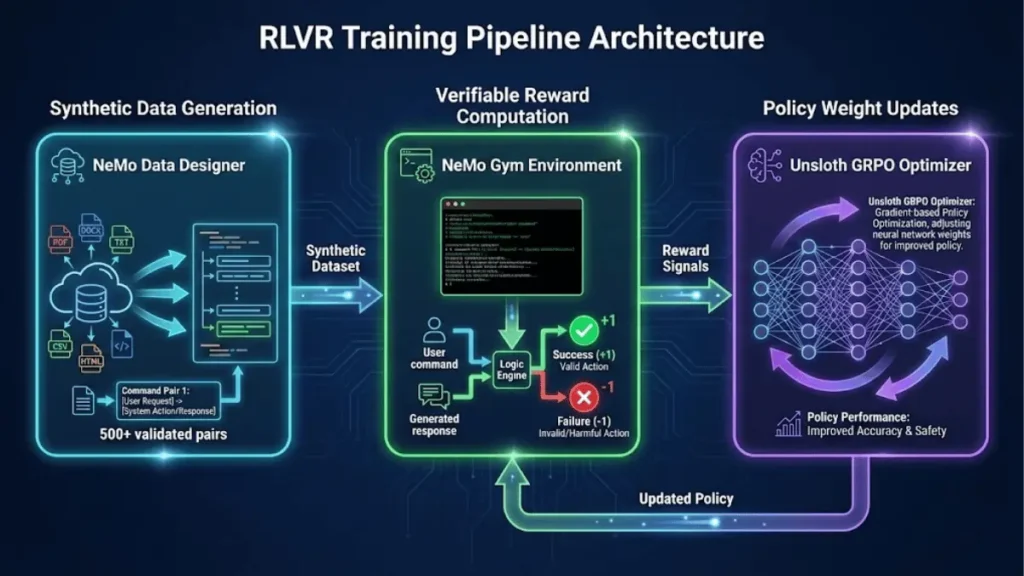
Training AI agents to operate command-line interfaces has historically required one of two compromises: either accept high error rates from generic models, or wait months collecting real usage logs. NVIDIA’s approach solves both problems through a three-component architecture that NVIDIA deployed to teach Nemotron-Nano-9B-V2 to operate LangGraph CLI commands with zero prior training data.
The data scarcity problem is acute for enterprise teams. Proprietary internal tools lack the massive training corpora that general-purpose models rely on. A standard DevOps CLI might have specific syntax for Docker orchestration, Kubernetes management, or infrastructure provisioning, none of which appears in public datasets. Traditional supervised learning would require thousands of human-labeled command pairs, a process taking 6-12 months for comprehensive coverage.
NVIDIA’s solution combines synthetic data generation via NeMo Data Designer with Reinforcement Learning with Verifiable Rewards (RLVR), optimized through Group Relative Policy Optimization (GRPO). This architecture trains production-ready agents in days, not quarters.

Architecture Component 1: Synthetic Data Generation with NeMo Data Designer
How Synthetic Training Data Eliminates the Cold-Start Problem
NeMo Data Designer programmatically generates training pairs from minimal seed examples typically 5-10 hand-crafted commands. The system uses a large teacher model (e.g., Nemotron-3-Nano-30B) to expand these seeds into hundreds of validated command pairs through controlled sampling and strict validation.
The generation process operates in three phases:
Phase 1: Seed Distribution Definition
Engineers define parameter ranges using Sampler objects. For LangGraph CLI training, NVIDIA defined:
pythoncommand = Sampler(["new", "dev", "up", "build", "dockerfile"])
port = Sampler(range(3000, 9000))
template = Sampler(["react-agent", "memory-agent", "retrieval-agent"])
Phase 2: Natural Language Generation
A teacher LLM generates diverse user requests matching these parameters. Example output: “Start a local dev server on port 8123 without opening a browser”.
Phase 3: Validation and Structured Output
Each generated command passes through regex validation (e.g., ^langgraph\s+(dev|build|up|dockerfile)\b) before dataset inclusion . Invalid outputs are rejected automatically, ensuring 100% syntactic correctness in the training set.
Why This Outperforms Manual Labeling
| Approach | Time to 500 Examples | Syntax Accuracy | Coverage Completeness |
|---|---|---|---|
| Manual human labeling | 40-60 hours | 85-92% (human error) | Biased toward common patterns |
| Synthetic generation (NeMo) | 1-2 hours | 100% (validated) | Exhaustive parameter coverage |
Research from NVIDIA indicates synthetic data closes critical gaps in low-resource domains like proprietary coding languages, achieving parity with human-labeled datasets while reducing preparation time by 95%.
Architecture Component 2: Reinforcement Learning with Verifiable Rewards (RLVR)
The Fundamental Difference from RLHF
Traditional Reinforcement Learning from Human Feedback (RLHF) trains a separate reward model to approximate human preferences, a subjective, expensive process requiring thousands of human comparisons. RLVR replaces human judges with deterministic code-based verification functions.
For CLI agents, the verifier enforces hard rules:
- Output must start with the correct binary name (e.g.,
langgraph) - Only approved subcommands and flags allowed
- No shell metacharacters (
&&,;,|) permitted - JSON structure must parse correctly
The reward function returns:
- +1.0 for syntactically correct, approved commands
- −1.0 for invalid syntax, unauthorized commands, or parsing failures
- 0.0 for ambiguous outputs requiring human review
Why Deterministic Verification Outperforms Learned Rewards
A 2025 study published in OpenReview demonstrated that RLVR extends model reasoning capabilities beyond simple memorization, with early-stage training dynamics showing 32% faster convergence on mathematical reasoning tasks compared to RLHF. The key advantage: verifiable rewards eliminate reward hacking, where models learn to exploit biases in learned reward models rather than solving the underlying task.
NVIDIA’s implementation uses binary validation for the LangGraph CLI:
pythondef compute_reward(agent_output, expected):
try:
cmd = json.loads(agent_output)
# Hard Rule: Command must match expectation
if cmd.name != expected.name:
return -1.0 # Penalize hallucinations
# Soft Rule: Flags must be accurate
accuracy = calculate_flag_accuracy(cmd.flags, expected.flags)
return accuracy
except JSONDecodeError:
return -1.0 # Penalize broken syntax
This approach scales to complex domains including code synthesis (test case execution), mathematical reasoning (symbolic checkers), and robotic manipulation (physics simulators).
Architecture Component 3: Group Relative Policy Optimization (GRPO)
How GRPO Reduces Memory Requirements by 80%
Traditional Proximal Policy Optimization (PPO) trains two models simultaneously: a policy network (the agent) and a critic network (value estimator). This dual-model architecture requires 2x memory and introduces training instability when the critic’s estimates diverge from true returns.
GRPO eliminates the critic entirely. Instead of learning a value function, GRPO samples multiple outputs for the same prompt and uses their average reward as the baseline for advantage estimation. This cuts memory usage in half while improving sample efficiency.
Performance Comparison: GRPO vs PPO

Research from LIACS (Leiden University) benchmarked GRPO against PPO across four reinforcement learning tasks:
| Task | GRPO Convergence Steps | PPO Convergence Steps | Speedup |
|---|---|---|---|
| CartPole | 15,000 | 25,000 | 1.67x faster |
| Acrobot | 80,000 | 120,000 | 1.50x faster |
| Catch | 40,000 | 60,000 | 1.50x faster |
| Breakout (MinAtar) | 140,000 | 180,000 | 1.29x faster |
Key Finding: GRPO achieves faster per-step learning because it updates more frequently (after each episode group terminates) rather than waiting for fixed-size rollout buffers.
The Variance Reduction Mechanism
When training the LangGraph CLI agent, NVIDIA observed a common pattern: For a single prompt like “Bring the LangGraph server online,” the model might generate 10 command variations:
- 9 invalid (reward = 0)
- 1 valid (reward = 1)
Traditional RL struggles with this signal-to-noise ratio. GRPO groups all 10 responses together and computes relative advantages:
where G is the group size (typically 10–16). The valid command receives a strong positive advantage (+0.9), while invalid attempts receive small negative advantages (−0.1 each). This amplifies the learning signal from rare successes.
Safety Architecture: Human-in-the-Loop Execution
Multi-Layered Defense Against Command Injection
NVIDIA’s framework enforces safety at four distinct stages:
Layer 1: Training-Time Safety
RLVR ensures the model learns to generate only validated command structures. The synthetic training data excludes any examples containing shell metacharacters or unauthorized binaries.
Layer 2: Runtime Validation
A pre-execution validator checks every proposed command against allowlists before presenting it to users.
Layer 3: Human Confirmation
The agent always requests explicit approval:
text[🤖] I can execute:
[COMMAND]
["langgraph", "up", "--wait"]
[CONFIRM]
Run this command now? (yes/no)
Layer 4: Execution Isolation
Commands execute via subprocess.run(argv, shell=False), treating shell operators as literal strings rather than executable syntax. This architecture makes command injection mathematically impossible even if the model hallucinates dangerous commands, they cannot execute.
Why This Matters for Enterprise Deployment
A 2025 survey by Label Studio found that 78% of enterprises cite security concerns as the primary blocker for AI agent adoption in production environments. NVIDIA’s human-in-the-loop architecture addresses this by ensuring users retain final approval authority while still benefiting from AI assistance.
Cost-Efficiency Analysis: RLVR vs Alternative Training Methods
Hardware and Time Requirements
| Training Approach | GPU Requirement | Training Duration | Data Collection Time | Total Time to Production |
|---|---|---|---|---|
| Supervised learning (manual labels) | 1x A100 (80GB) | 6-12 hours | 30-90 days | 30-90 days |
| RLHF (human feedback) | 2x A100 (160GB total) | 24-48 hours | 14-30 days | 14-30 days |
| RLVR + GRPO (NVIDIA) | 1x A100 (80GB) | 4-8 hours | 0 days (synthetic) | 1-2 days |
Cost Implication: At $3.00/hour for A100 cloud GPU time (AWS p4d.24xlarge rates), RLVR reduces training costs from $600-1,500 (RLHF) to $24-48 per specialized agent.
When RLVR Provides the Strongest ROI
RLVR excels in three scenarios:
- Proprietary internal tools where no public training data exists
- Safety-critical applications requiring deterministic correctness guarantees
- Rapid prototyping where time-to-deployment matters more than marginal accuracy gains
RLVR underperforms in creative tasks with subjective quality criteria (e.g., marketing copy generation, artistic style transfer) where human preferences cannot be formalized as code.
Implementation Workflow: From Zero to Production Agent
Step-by-Step Deployment Path
Stage 1: Environment Setup (30 minutes)
Install CUDA 12.0+, Python 3.10+, and core dependencies:
- LangGraph (target CLI tool)
- NeMo Gym (RL training environment)
- Unsloth (GRPO optimization)
- NeMo Data Designer (synthetic data generation)
Stage 2: Synthetic Dataset Generation (2 hours)
Define 5-10 seed commands → Generate 500-1000 validated pairs → Export to OpenAI messages format.
Stage 3: RLVR Fine-Tuning (4-8 hours)
Load Nemotron-Nano-9B-V2 → Configure verifiable reward function → Execute GRPO training loop → Validate on held-out test commands.
Stage 4: Human-in-the-Loop Integration (2 hours)
Wrap trained model with confirmation prompts → Implement subprocess execution with shell=False → Deploy to target environment.
Total Timeline: 8-12 hours from project start to functional CLI agent.
Strategic Outlook: When to Deploy RLVR-Trained Agents
The Buy/Wait/Skip Framework
Buy Now (Deploy RLVR) If:
- You need agents for proprietary CLI tools with no public training data
- Command correctness is binary and programmatically verifiable
- Your team has GPU access (single A100 or equivalent)
- Time-to-market pressure requires deployment in days, not months
Wait (Monitor Development) If:
- Your target task has subjective quality criteria requiring human judgment
- Existing general-purpose models (GPT-4, Claude) already achieve >90% accuracy on your use case
- Budget constraints prevent GPU training infrastructure investment
Skip (Use Alternatives) If:
- Your application requires creative, open-ended generation (e.g., content marketing)
- Task complexity exceeds what verifiable rewards can capture (e.g., strategic business planning)
- You already have large, high-quality human-labeled datasets for supervised learning
The Broader Implications for Enterprise AI
NVIDIA’s framework signals a shift from data-centric to architecture-centric AI development. By eliminating data collection bottlenecks, enterprises can deploy specialized agents for internal tooling at unprecedented speed. The key constraint becomes engineering expertise (defining reward functions and validation logic) rather than dataset availability.
Research from NVIDIA indicates this approach generalizes beyond CLI agents to domains including robotic manipulation (physics-based rewards), code synthesis (test case execution), and mathematical reasoning (symbolic verification). The unifying principle: any task with deterministic correctness criteria can benefit from RLVR training.
Reinforcement Learning with Verifiable Rewards (RLVR) trains AI agents using deterministic code-based verification instead of human feedback, enabling specialized CLI automation in hours rather than months. NVIDIA’s framework combines synthetic data generation, GRPO optimization, and human-in-the-loop safety for production-ready deployment on single-GPU infrastructure.
Data Tables
Training Method Comparison
| Method | Data Source | Training Time | GPU Memory | Reward Type | Best Use Case |
|---|---|---|---|---|---|
| Supervised Learning | Human-labeled | 6-12 hrs | 80GB | N/A (loss-based) | General tasks with abundant labels |
| RLHF | Human feedback | 24-48 hrs | 160GB | Learned (subjective) | Creative tasks, content generation |
| RLVR + GRPO | Synthetic | 4-8 hrs | 80GB | Deterministic | CLI tools, code, math reasoning |
NeMo Framework Component Roles
| Component | Function | Key Advantage | Production Readiness |
|---|---|---|---|
| NeMo Data Designer | Generates validated synthetic training pairs | 95% faster than manual labeling | GA (Generally Available) |
| NeMo Gym | Provides RL training environments with tool definitions | Deterministic reward computation | GA |
| Unsloth (GRPO) | Executes memory-efficient policy optimization | 80% less VRAM than PPO | Open Source |
| Nemotron-Nano-9B-V2 | Base reasoning model for fine-tuning | Efficient inference at 9B parameters | Public (Hugging Face) |

{kind=link}
Frequently Asked Questions (FAQs)
What is RLVR and how does it differ from RLHF?
RLVR (Reinforcement Learning with Verifiable Rewards) uses deterministic code-based verification instead of learned reward models, eliminating reward hacking and reducing training complexity by 50%.
Can synthetic data fully replace real-world training examples?
For structured tasks with clear correctness criteria (CLI commands, math problems, code synthesis), synthetic data achieves parity with human labels while reducing preparation time by 95%.
Why does GRPO use less memory than PPO?
GRPO eliminates the critic network required by PPO, using group-averaged rewards as baselines instead. This cuts VRAM requirements by 80% while improving convergence speed.
What hardware is required to train a CLI agent with RLVR?
Minimum: 1x NVIDIA A100 GPU (80GB), 32GB system RAM, 100GB disk space. Training completes in 4-8 hours for domain-specific CLI tools.
Is human-in-the-loop approval necessary for production deployment?
Yes for safety-critical environments. NVIDIA’s architecture requires explicit user confirmation before executing any command, preventing unauthorized actions even if the model hallucinates dangerous outputs.
Which tasks benefit most from RLVR training?
Tasks with binary correctness criteria: CLI automation, mathematical reasoning, code synthesis, and robotic manipulation. RLVR underperforms in creative tasks requiring subjective human judgment.