
THE QUICK BRIEF
The Core Technology:
Generative AI implementation is the systematic deployment of large language models (LLMs) and multimodal AI systems into enterprise workflows using structured frameworks like MLOps, Use-Case Maturity Framework (UCMF), and Responsible AI Implementation Framework (RAIF).
Key Implementation Metrics:
- Average ROI: 3.7x return on every $1 invested
- Typical Timeline: 6-24 months depending on architecture strategy
- Success Rate: Only 5% of enterprise GenAI pilots successfully scale beyond experimentation
- Monthly Data Incidents: 223 AI-related security violations per organization on average
- Cost Range: $50,000-$2M initial investment; 10-40% annual maintenance
The Bottom Line:
Production-ready for enterprises with structured frameworks, dedicated governance, and iterative deployment. Experimental for organizations lacking data infrastructure maturity or cross-functional AI teams. The 95% failure rate stems from integration gaps and organizational friction, not model limitations.
Why Generative AI Implementation Matters Now
Generative AI adoption has tripled in 2026, yet enterprises face a critical implementation divide. Organizations implementing GenAI with structured frameworks achieve 40% effort savings in testing, 50% year-on-year growth acceleration, and $7.5M in five-year cost reductions. However, 95% of pilots fail because companies avoid the organizational friction required to integrate AI into existing workflows. The challenge is no longer if to deploy generative AI, but how to architect systems that learn from workflows, maintain data governance, and deliver measurable CFO-level outcomes.
Architecture Strategy Comparison
Selecting the right deployment architecture determines both implementation velocity and long-term total cost of ownership (TCO).
| Approach | Initial Investment | Ongoing Costs | Control Level | Time to Value | Risk Profile |
|---|---|---|---|---|---|
| Custom Development | $500K-$2M | 30-40% annually | Maximum | 12-24 months | High technical risk |
| Strategic Partnership | $100K-$500K | 15-25% annually | Shared | 6-12 months | Medium implementation risk |
| Commercial Platform | $50K-$200K | 10-20% annually | Limited | 3-6 months | Low technical, high vendor lock-in risk |
Custom development provides maximum architectural control but demands specialized talent pools commanding $300K-$500K annual compensation. Strategic partnerships balance flexibility with faster deployment through domain-specific expertise. Commercial platforms (Vertex AI, Azure OpenAI Service, AWS Bedrock) offer lowest technical risk but limit model customization and create vendor dependencies.

The Five-Phase Implementation Framework
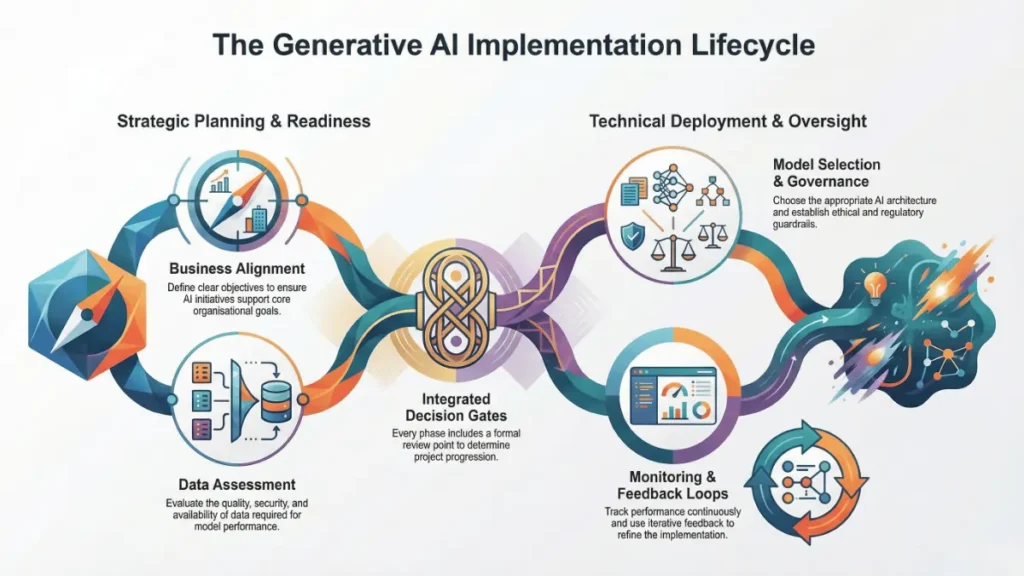
Phase 1: Business Alignment and Use-Case Prioritization
Successful implementations begin by linking AI initiatives to CFO-level objectives rather than technology capabilities. Identify three measurable business outcomes such as 15% reduction in service costs, 5% decrease in days sales outstanding, or 10% boost in digital conversion. Apply the Use-Case Maturity Framework (UCMF) to score potential applications based on complexity, data quality, compliance requirements, and expected ROI.
Prioritize use-cases demonstrating both high business impact and technical feasibility. Sojern reduced audience generation time from two weeks to under two days while improving cost-per-acquisition by 20-50% by focusing on real-time traveler intent signals using Vertex AI and Gemini models. ROSHN Group’s internal assistant RoshnAI leveraged Gemini 1.5 Pro to generate insights from proprietary data sources, supporting strategic planning for 45,000 registered users.
Phase 2: Data Infrastructure Assessment
Data quality determines generative AI accuracy more than model selection. Assess existing data pipelines for completeness, formatting consistency, and accessibility. Data collection and cleaning consume 10-15% of total AI budgets, while data engineering represents 25-40% of implementation spend.
Establish data governance policies addressing privacy regulations, secondary data usage restrictions, and intellectual property protection. Organizations lacking enforceable AI data policies experience an average of 223 monthly security incidents, with 42% involving source code exposure and 32% regulated data leaks. Implement data loss prevention (DLP) solutions that inspect content flowing to AI applications and block unauthorized transfers.
Phase 3: Model Selection and Deployment Architecture
Select models based on task-specific requirements, budget constraints, and context window needs.
| Model | Context Window | Input Pricing (per 1M tokens) | Output Pricing (per 1M tokens) | License Type |
|---|---|---|---|---|
| GPT-4o | 128K | $2.50-$5.00 | $10.00-$15.00 | Proprietary |
| Claude Opus 4.5 | 200K | $20.00 | $100.00 | Proprietary |
| Gemini 3 Pro | 2M | $2.00 | $12.00 | Proprietary |
| Gemini 2.5 Flash-Lite | 1M | $0.10 | $0.40 | Proprietary |
Gemini Flash-Lite offers the most cost-effective solution for high-volume production workloads, with input costs 33% lower than competing budget-tier models. Gemini 3 Pro handles 2M token context windows ideal for comprehensive document analysis and multimodal processing. GPT-4o and Claude Opus 4.5 serve specialized enterprise applications requiring complex reasoning or high-precision outputs.
Deploy using federated teams with centralized governance to balance global control with local innovation. Implement MLOps pipelines for standardized model development, deployment, monitoring, and continuous improvement. Gazelle increased output accuracy from 95% to 99.9% and reduced content generation time from four hours to 10 seconds using Gemini models for property document extraction, saving brokers 4-6 hours of manual work per property.
Phase 4: Governance and Security Framework
Embed governance, security, and compliance requirements at the architecture design phase. Implement zero-trust architecture ensuring AI systems access data only through secure gateways with role-based permissions and immutable audit logs. Address hallucination risks through Retrieval-Augmented Generation (RAG) and hallucination-aware fine-tuning pipelines.
RAG-HAT (Hallucination-Aware Tuning) reduces hallucination rates by approximately 7.2% in F1-score and 17% in precision through detection models that identify information conflicts. Deploy prompt engineering techniques including role-based prompting and few-shot learning to improve response accuracy. Establish human-in-the-loop approval processes for high-stakes decisions requiring oversight.
Designate an AI product owner for each business objective and define parameters for brand consistency, risk tolerance, and compliance boundaries. A global insurance leader achieved 40% effort savings, 35% optimized regression testing, and 32% overall QA cost savings through governance-driven generative AI testing processes.
Phase 5: Continuous Monitoring and Optimization
Implement bi-weekly evaluation cycles monitoring delivered value, reduced cycle times, required approvals, raised exceptions, and risk indicators. Track both technical metrics (model drift, latency, token consumption) and business KPIs (cost reduction, revenue impact, customer satisfaction).
Model maintenance including drift detection and retraining automation adds 15-30% to operational costs annually. Five Sigma achieved 80% error reduction, 25% increase in adjuster productivity, and 10% reduction in claims cycle processing time through continuous AI engine refinement. Expand implementations only when metrics demonstrate favorable performance across technical and business dimensions.
Total Cost of Ownership Breakdown
Understanding where AI budgets are allocated is critical for long-term ROI planning.
Six Components of AI TCO:
- Infrastructure (20-35% of total): GPU clusters, auto-scaling, multi-cloud deployments costing $200K-$2M+ annually
- Data Engineering (25-40%): Pipeline processing, quality monitoring, and data acquisition
- Talent Acquisition (25-35%): Specialized AI engineers commanding $300K-$500K compensation packages
- Model Maintenance (15-30%): Drift detection, retraining automation, and performance monitoring
- Compliance and Governance (5-10%): Up to 7% revenue penalty risk for violations
- Integration Complexity (10-20%): Legacy system connections carrying 2-3x implementation premium
ROI Calculation Formula:
Net Benefits = Total Benefits – Total Costs
Enterprises investing in generative AI report an average 3.7x return for every dollar spent. Identify AI investment costs across development (data acquisition, software, tools), personnel (vendors, data scientists), infrastructure (cloud computing, storage), and maintenance before deployment.
Hardware Requirements for Self-Hosted Deployment
Organizations pursuing custom deployment architectures require specific hardware configurations.
| AI Application | CPU Requirement | GPU Requirement | VRAM | Memory | Storage |
|---|---|---|---|---|---|
| GPT-4 Class Models | Intel Core i9, AMD Ryzen 9 | NVIDIA RTX 40 series or higher | 16GB+ | 64GB+ | SSD 2TB+ |
| Image Generation (Stable Diffusion) | Intel Core i7, AMD Ryzen 7 | NVIDIA RTX 30/40 series | 8-16GB | 16GB+ | SSD 512GB+ |
| Production Inference | NVIDIA RTX 50 series, RTX 6000 ADA | High VRAM (24GB+) | 256-bit+ Memory Bandwidth | Fast PCIe Gen 4/5 | NVMe SSD |
NVIDIA tensor cores and AMD compute units handle floating-point calculations (FP16) required for generative AI workloads. Systems built on NVIDIA RTX 50-series, RTX 6000 ADA, or AMD Threadripper/Xeon processors provide necessary PCIe bandwidth for multi-GPU configurations. Cloud-based deployments eliminate upfront hardware costs but add 10-15% to total AI budgets unless utilization remains high.
Common Implementation Failures and Mitigation Strategies
MIT research reveals 95% of generative AI pilots fail not due to model quality, but because organizations avoid the organizational friction necessary for enterprise integration. The “learning gap” occurs when generic tools like ChatGPT don’t adapt to organizational workflows, and companies fail to invest in systems that learn from their specific business contexts.
Critical Failure Points:
- Lack of Strategic Alignment: AI initiatives disconnected from measurable business outcomes fail to secure continued funding
- Poor Data Quality: Incomplete, inaccurate, or poorly formatted data produces subpar model outputs
- Skill Gaps: Organizations lack internal expertise in data science, ML engineering, and AI operations
- Integration Challenges: Connecting GenAI models with existing infrastructure requires more effort than anticipated
- Shadow AI Proliferation: 47% of GenAI users rely on personal AI applications operating outside organizational visibility
Mitigation Strategies:
Deploy iterative development cycles starting with high-impact, low-complexity use cases. Invest in training programs to build internal AI literacy or partner with experienced AI service providers. Implement approved AI tools meeting productivity needs to reduce shadow AI temptation. Establish clear data governance policies with technical enforcement through DLP solutions. Custom AI solutions addressing specific business needs improve success rates compared to off-the-shelf tools lacking flexibility.
AdwaitX Verdict: Deploy, Wait, or Research
Deploy Now:
Organizations with mature data infrastructure, dedicated cross-functional teams, and clearly defined CFO-level objectives should implement generative AI using structured frameworks (MLOps, UCMF). Focus on high-ROI applications like customer service automation, document processing, and code generation where case studies demonstrate 20-50% efficiency gains.
Strategic Wait:
Companies lacking enforceable data governance policies or experiencing shadow AI proliferation should establish security controls before expanding pilots. The 223 monthly security incidents and 95% failure rate indicate immature implementations create more risk than value.
Continue Research:
Emerging capabilities in agentic AI systems, 2M+ context windows, and hallucination mitigation techniques warrant monitoring. API pricing decreased significantly in recent years, suggesting continued cost reductions favor delayed adoption for price-sensitive applications.
Future Implications:
Generative AI implementation success depends on organizational learning capacity rather than model sophistication. The shift toward agentic operating models coordinating specialized agents within existing workflows (CRM, ERP, contact centers) represents the next evolution beyond standalone chatbots. Regulatory frameworks addressing AI transparency, bias mitigation, and data sovereignty will increasingly influence deployment architectures. Organizations building governance-first foundations position themselves for sustainable competitive advantage as AI capabilities mature.

{kind=link}
Frequently Asked Questions (FAQs)
How much does generative AI implementation cost?
Initial investment ranges from $50,000 for commercial platforms to $2M for custom development, with 10-40% annual maintenance costs depending on architecture complexity and infrastructure requirements.
Which generative AI model should businesses choose?
Select based on context window needs and budget: Gemini Flash-Lite ($0.10/$0.40 per 1M tokens) for high-volume workloads, Gemini 3 Pro (2M context) for document analysis, or GPT-4o/Claude Opus for specialized applications.
What hardware is required for self-hosted generative AI?
Minimum NVIDIA RTX 30/40 series GPU with 16GB+ VRAM, Intel Core i7/i9 or AMD Ryzen 7/9 CPU, 64GB+ memory, and NVMe SSD storage for production deployments.
How can businesses measure generative AI ROI?
Calculate Net Benefits (Total Benefits – Total Costs) tracking metrics like cost reduction percentage, cycle time improvements, error rate decreases, and productivity gains. Average enterprise ROI is 3.7x.
What causes most generative AI implementation failures?
95% of failures stem from organizational friction and integration gaps, not model quality. Companies avoid investing in systems that learn from specific business contexts, lacking strategic alignment and data quality.
How do companies prevent AI data security incidents?
Implement data loss prevention (DLP) solutions, zero-trust architecture with role-based access, approved AI tools to eliminate shadow AI (used by 47% of workers), and governance policies blocking sensitive data transfers.